
Analysis of Agibot’s Genie Envisioner and Figure AI’s Helix Models for Generalist Robotics
Published:
Originally published on Substack.

1. Executive Summary
The field of robotics is undergoing a transformative shift from specialized automation to general-purpose, adaptable systems. This report provides an expert-level analysis and comparison of two prominent models at the forefront of this evolution: Agibot's Genie Envisioner (GE) and Figure AI's Helix. Both models represent significant advancements in embodied AI, yet they approach the challenge of generalist robotics from distinct philosophical and architectural standpoints.
Genie Envisioner (GE) is introduced as a pioneering unified world foundation platform for robotic manipulation.1 Its core innovation lies in integrating policy learning, evaluation, and simulation within a single, closed-loop video-generative framework. This architecture, comprising GE-Base (world model), GE-Act (action model), and GE-Sim (simulator), is meticulously designed to capture the complex spatial, temporal, and semantic dynamics of real-world robotic interactions. GE emphasizes vision-centric world modeling to achieve precise control and robust cross-embodiment generalization with minimal new data.1
In contrast, Helix, developed by Figure AI, is presented as a generalist Vision-Language-Action (VLA) model specifically engineered for humanoid control.5 It unifies perception, natural language understanding, and learned control, aiming to enable humanoids to reason and operate with human-like capabilities in highly unstructured environments, particularly the home.6 Helix's distinctive dual-system architecture, while operating as a single neural network, allows for both high-level conceptual reasoning and precise, high-rate physical control across the entire upper body, including individual fingers. Its design prioritizes on-the-fly behavior generation and multi-robot collaboration for novel tasks.5
This report will highlight the fundamental divergence in their core paradigms: GE's focus on a predictive "world model" versus Helix's direct "Vision-Language-Action" mapping. It will compare their distinct generalization strategies (cross-embodiment versus cross-task/object), control granularities, and primary application domains. Both models represent significant advancements, pushing the boundaries towards more versatile and adaptable robotic systems. These innovations collectively accelerate the trajectory of general-purpose robotics, promising more efficient development cycles, expanded deployment capabilities into complex human environments, and more intuitive human-robot interaction, thereby laying critical groundwork for the next generation of embodied AI.
2. Introduction to Generalist Robotics and Embodied AI
The historical landscape of robotics has largely been characterized by systems confined to highly structured, repetitive tasks within controlled industrial environments. Traditional approaches often rely on extensive manual programming or the collection of vast, task-specific datasets, leading to what has been described as "fragmentation in existing robotic learning pipelines".3 This fragmentation results in significant "inefficiencies and limited scalability" when these systems are confronted with the inherent complexity and unpredictability of real-world environments.3 The cost and effort associated with teaching robots even a single new behavior have been prohibitively high, demanding "hours of PhD-level expert manual programming or thousands of demonstrations".5
This inherent limitation has spurred a paradigm shift towards generalist AI in robotics. The emerging imperative is for robots capable of learning, adapting, and performing diverse tasks in unpredictable, dynamic environments. A particularly challenging yet crucial domain for this new generation of robots is the home, which presents "robotics' greatest challenge" due to its "countless objects—delicate glassware, crumpled clothing, scattered toys—each with unpredictable shapes, sizes, colors, and textures".5 Such environments necessitate a fundamental change, moving beyond rigid programming to enable on-demand, intelligent behavior generation.5 The ability to succeed in the highly unstructured, unpredictable, and diverse home environment serves as the most comprehensive validation of a robot's "generalist" capabilities. Achieving proficiency in this domain is a strong indicator of true general-purpose AI in physical embodiments, which stands in stark contrast to the controlled settings of traditional industrial robotics.5 This environmental complexity directly drives the need for advanced generalist AI models that prioritize on-the-fly generalization, natural language understanding, and robust manipulation of novel objects.
Within this evolving landscape, two primary conceptual frameworks are gaining prominence: World Models and Vision-Language-Action (VLA) systems. World Models are AI systems that learn an internal representation of the environment, enabling them to predict future states based on actions. This predictive capability is foundational for planning, reasoning, and simulation.1 Conversely, VLA Models are integrated systems that directly translate multimodal inputs, such as visual observations and natural language instructions, into executable robot actions. These models leverage large-scale pre-training to acquire broad common-sense understanding, facilitating intuitive control.5 Agibot's Genie Envisioner exemplifies the world model approach, while Figure AI's Helix embodies the VLA paradigm. This report aims to provide a comprehensive, expert-level analysis and comparison of these two leading examples, dissecting their technical contributions and strategic implications for the field of embodied intelligence.
3. Genie Envisioner (Agibot): A Unified Video-Generative World Platform
3.1. Core Concept and Vision: Unified Platform for Robotic Manipulation
Genie Envisioner (GE) is introduced as a "unified world foundation platform for robotic manipulation".1 Its foundational vision is to integrate "policy learning, evaluation, and simulation within a single video-generative framework," effectively collapsing "robot sensing, policy learning, and evaluation into a single closed-loop video generative world model".1 AgiBot's philosophy underpinning this design is that "World models for robotics should learn, act, and evaluate in one loop".4 This integrated design directly addresses the "fragmentation in existing robotic learning pipelines, which typically separate data collection, policy training, and evaluation, resulting in inefficiencies and limited scalability".3
The emphasis on a unified, closed-loop system is a strategic architectural choice that offers a significant advantage. By having learning, acting, and evaluating continuously inform each other within a singular framework, GE fosters a faster iteration cycle for robot skill acquisition and refinement. This integrated design allows the simulator, GE-Sim, to be directly tied to the world model, GE-Base, and the action model, GE-Act. This tight coupling means GE can potentially generate vast amounts of synthetic data for training and evaluation, thereby reducing reliance on costly and time-consuming real-world demonstrations. This approach represents a direct and potent response to the pervasive scalability challenges that have historically plagued traditional robotics.
3.2. Architectural Deep Dive: GE-Base, GE-Act, and GE-Sim
GE's architecture is modular, comprising three tightly coupled components 2:
GE-Base (World Foundation Model): This serves as the core of the platform, functioning as a large-scale, instruction-conditioned video diffusion model or transformer.1 Its primary purpose is to capture the spatial, temporal, and semantic dynamics of real-world robotic interactions within a structured latent space.1 GE-Base is trained on an extensive dataset of approximately 3,000 hours of video-language paired data, encompassing over one million real-world robotic manipulation episodes from the proprietary AgiBot-World-Beta dataset.1 The model formulates robotic world modeling as a text-and-image-to-video generation problem.3 It incorporates a sparse memory mechanism to encode long-term temporal dependencies and processes multi-view inputs (e.g., head, left, right cameras) via a shared video encoder with cross-view attention to ensure spatial consistency.2
GE-Act (World Action Model): This component is a lightweight, flow-matching decoder responsible for translating the latent representations generated by GE-Base into executable action trajectories.1 GE-Act's functionality involves converting visual latent features, conditioned on language instructions, into fine-grained and low-latency motor commands.1 This enables a direct and efficient mapping from perception and instruction to physical actions. The system operates over noise-initialized latent action tokens, which are then refined through cross-attention mechanisms to produce precise control signals.2
GE-Sim (World Simulator): As a video-based neural simulator, GE-Sim facilitates closed-loop execution and evaluation within the unified framework.1 Its key capability is to provide rapid evaluation of control policies by simulating instruction-driven manipulation tasks with high physical and visual realism.2 GE-Sim utilizes projected spatial pose conditions, often encoded via networks like CLIP, and concatenates them with historical visual context to synthesize temporally coherent and physically plausible video sequences conditioned on action inputs.2 A notable aspect of GE-Sim's training is its initialization from a high-temporal-resolution GE-Base-MR and its training on diverse, failure-augmented data.3 This inclusion of failure scenarios in the training data is a subtle yet critical detail. By explicitly modeling how actions can go wrong, GE-Sim learns not just successful outcomes but also failure modes, which enhances the robustness and realism of the simulator. This proactive strategy for developing more resilient and safer robot behaviors in real-world scenarios provides more valuable feedback for policy learning.
3.3. Key Technical Innovations
Genie Envisioner introduces several key innovations that distinguish its approach to embodied AI:
Unified Video-Generative Framework: The integration of prediction, policy learning, and neural simulation into a single, coherent video-generative platform is highlighted as a "first of its kind in the industry".2 This creates a "unified video-based robotic vision space" that preserves detailed spatial and temporal cues, facilitating end-to-end policy learning and evaluation within a single, coherent platform.1
Asynchronous Inference (Slow-Fast Mode): This novel mode optimizes computational efficiency by exploiting asymmetries in denoising complexity and target frequency.1 It effectively bridges the temporal gap between visual processing and motor control, enabling the real-time generation of 54-step torque trajectories within 200 ms on commodity hardware.2 This low-latency capability is paramount for reactive and precise robotic manipulation, especially in dynamic environments or for tasks requiring fine-grained control. By optimizing computational efficiency and temporal synchronization, GE's asynchronous inference makes its complex video-generative approach practical for real-world deployment, setting it apart from purely offline or high-latency generative models.
Cross-Embodiment Generalization: GE demonstrates precise task execution on its in-domain AgiBot G1 platform and exhibits strong generalization capabilities to novel robotic systems, including Dual Franka and Agilex Cobot Magic.1 This remarkable adaptability requires "only 1 hour of embodiment- and task-specific teleoperation data for post-training," significantly reducing the effort and data traditionally needed for new hardware.1 This is achieved by establishing a mapping from language instructions to an embodied visual space, capturing the essence of robotic manipulation by modeling the spatial, temporal, and semantic regularities of real-world interactions.1
Open-Source Commitment: AgiBot has announced plans to make all code, models, and benchmarks related to the platform open source.4 This strategic decision could significantly accelerate research and development across the entire robotics community, fostering rapid iteration, broader adoption, and potentially establishing GE's framework as an industry standard for world modeling in manipulation.
3.4. Demonstrated Capabilities and Performance Metrics
Genie Envisioner has demonstrated impressive capabilities and performance across various benchmarks and real-world scenarios:
Complex Manipulation Tasks: GE successfully executes intricate manipulation tasks, including fine-grained control of deformable objects and memory-based decision making. Examples include stacking a deformable box, placing a target object inside based on instruction, and closing the lid, even when the object becomes occluded.1
Superior Baseline Performance: The system achieves superior performance on the AgiBot G1 platform, outperforming state-of-the-art VLA baselines such as UniVLA and GR00T N1 in both step-wise and end-to-end success rates across various household and industrial tasks.3
Video Generation Fidelity: GE-Base consistently surpasses other leading video generation models, including Open-Sora, Kling, Hailuo, COSMOS, and LTX-Video, in critical metrics such as temporal alignment, dynamic consistency, and control-aware generation fidelity.3
Advanced Task Planning: The platform enables robots to achieve advanced task planning capabilities, exemplified by its performance in tasks like folding clothes and conveyor belt sorting.4
Real-World Validation: Extensive real-world experiments confirm GE's superior performance in both in-domain and cross-embodiment scenarios, positioning it as a practical platform for advancing embodied intelligence.3
4. Helix (Figure AI): A Generalist Vision-Language-Action Model for Humanoids
4.1. Core Concept and Vision: Generalist VLA for Humanoid Control
Helix is introduced as a "generalist Vision-Language-Action (VLA) model that unifies perception, language understanding, and learned control".5 Its primary objective is to "overcome multiple longstanding challenges in robotics" 5 by enabling humanoid robots to "reason and operate with human-like capabilities".6 A key strategic aim for Helix is to scale robotics from "controlled industrial environments to the unpredictable, varied settings of homes," directly addressing the vast complexity and unpredictability of household tasks.5 Figure AI's broader vision includes deploying a fleet of autonomous humanoids to address rising labor shortages and fill "jobs that humans don't want to perform," ultimately integrating humanoids into corporate labor, in-home assistance, and elderly care.8
The strategic focus on the home environment for Helix is a profound declaration of intent to tackle the most complex, unstructured, and diverse domain for robotics. This implies that Helix is specifically designed to handle extreme variability, interact with novel objects, and engage in complex human-like interactions. This emphasis on the home pushes the boundaries of what a VLA model needs to achieve to be truly "generalist," demanding robust generalization, adaptability, and common-sense reasoning. Success in this highly challenging environment serves as the ultimate validation of a robot's generalist capabilities, positioning Figure AI as aiming for a broader societal impact beyond traditional industrial automation.
4.2. Architectural Deep Dive: Dual-System Architecture and Single Neural Network
A distinguishing feature of Helix is its use of "a single set of neural network weights to learn all behaviors—picking and placing items, using drawers and refrigerators, and cross-robot interaction—without any task-specific fine-tuning".5 This unified approach represents a significant departure from traditional robotics, which often requires separate models or extensive fine-tuning for each new task or object. By consolidating diverse behaviors into a single network, Helix leverages shared representations and knowledge across tasks, leading to more robust generalization and reducing the expensive effort previously required to scale robot capabilities. This points towards a future of truly emergent, adaptable intelligence rather than pre-programmed or extensively demonstrated behaviors.
Helix employs a dual-system architecture, explicitly inspired by Daniel Kahneman's "Thinking, Fast and Slow" framework 6:
System 2 ("Big Brain"): This is a 7-billion-parameter Vision-Language Model (VLM) pretrained on internet-scale data.6 System 2 is responsible for high-level reasoning, language comprehension, and visual interpretation. It enables Helix to process abstract commands, such as "Pick up the desert item," and translate them into actionable steps by identifying relevant objects and contexts.6
System 1 (Visuomotor Policy): This is an 80-million-parameter model optimized for fast, low-level control.6 System 1 executes precise physical actions, such as grasping or manipulating objects, based on directives from System 2.6 Its smaller size is crucial for ensuring the rapid response times necessary for real-time robotic operations.
The fundamental challenge in generalist robotics is effectively bridging the gap between high-level semantic understanding (e.g., interpreting complex natural language commands) and low-level, real-time physical execution (e.g., precise grasping and coordinated full-body movement). A single, monolithic model might struggle to satisfy both the computational demands of deep reasoning and the latency requirements of real-time control. By separating these concerns into a "deliberative" System 2 and a "reflexive" System 1, Helix effectively parallelizes and optimizes these distinct computational demands. This architectural choice allows Helix to simultaneously achieve "on-the-fly behavior generation" (driven by System 2's ability to interpret novel commands and contexts) and "high-rate continuous control" (enabled by System 1's capacity for precise physical actions at 200Hz).6 This hierarchical cognitive architecture, mirroring human thought processes, is a highly effective and scalable design pattern for complex, generalist humanoid tasks in dynamic and unpredictable environments.
Crucially, both System 1 and System 2 run entirely on embedded low-power-consumption GPUs.5 This design choice makes Helix commercially viable for immediate deployment without reliance on external computing resources or cloud dependency, minimizing latency and maximizing autonomy.7
4.3. Key Technical Innovations and "Firsts"
Helix introduces several "firsts" and key technical innovations that significantly advance humanoid robotics:
Full-Upper-Body Control: Helix is highlighted as the "first VLA to output high-rate continuous control of the entire humanoid upper body".5 This includes precise control over wrists, torso, head, and individual fingers, encompassing 35 degrees of freedom (DoF).6 This level of control enables "stunning precision" and "graceful" movement, crucial for human-like dexterity and interaction in human-centric environments.7
Multi-Robot Collaboration: It is the "first VLA to operate simultaneously on two robots," enabling them to collaboratively solve shared, long-horizon manipulation tasks with items they have never seen before.5 A single Helix instance can control multiple robots, demonstrating robust internal representations of the world and actions to manage distributed control and shared goals.7 This feature is crucial for complex, real-world tasks that often require multiple agents or hands, increasing the complexity of tasks that can be performed and improving efficiency and throughput for commercial and household applications.
"Pick Up Anything" Generalization: Figure robots equipped with Helix can pick up virtually any small household object, including thousands of previously unencountered items, simply by following natural language prompts.5 This capability is a direct result of Helix's "on-the-fly behavior generation," which allows it to generate intelligent, novel behaviors for objects it has never seen, significantly reducing the traditional need for extensive human effort in programming or collecting thousands of demonstrations.6 This fundamentally alters robotics' scaling trajectory.5
Direct Translation of VLM Knowledge: Helix is explicitly built to "bridge this gap" by extracting rich common-sense knowledge captured in Vision-Language Models (VLMs) and translating it directly into generalizable robot actions.5
Commercial Readiness: The ability to run entirely on embedded, low-power-consumption GPUs makes Helix commercially viable for immediate real-world application, avoiding the latency and dependency issues of cloud-based systems.5
4.4. Demonstrated Capabilities and Performance Metrics
Helix has demonstrated a wide range of capabilities and strong performance, particularly within humanoid platforms:
Collaborative Grocery Storage: A compelling demonstration involves two robots, both controlled by a single Helix instance, working together to store groceries they have never encountered before, showcasing advanced coordination and adaptability.5
Diverse Object Manipulation: Robots powered by Helix perform various household item manipulations, including picking and placing items into containers, operating drawers, and interacting with refrigerators, all based on natural language instructions.6
Conceptual Reasoning: In an illustrative example, Helix interprets the abstract command "Pick up the desert item" and correctly selects a toy cactus, highlighting its ability to connect abstract language to physical actions and common-sense understanding.6
High-Rate Control: Helix achieves high-rate control at 200Hz for its 35 DoF action space, enabling fluid and precise movements.6
Humanoid Platform Capabilities: Figure 01 and Figure 02 humanoids, powered by Helix, demonstrate a range of capabilities such as walking, lifting, moving objects, making coffee, and folding laundry.8 Figure 02, the successor, features a fourth-generation hand design, a six-camera computer vision system, and can carry up to 25 pounds per hand, operating for up to 10 hours on a 2.25 KWh battery.8
Industrial Deployment: Figure 02 was successfully deployed for testing at a BMW factory, where it learned and completed various assembly tasks, including inserting sheet metal parts into pre-set fixtures.8
5. Comparative Analysis: Genie Envisioner vs. Helix
5.1. Fundamental Paradigms: World Model vs. VLA Approaches
The most fundamental distinction between Genie Envisioner and Helix lies in their core paradigms for achieving embodied intelligence. Genie Envisioner operates on a world model approach.1 Its strategy revolves around learning a predictive model of the environment (GE-Base) through high-fidelity video generation. Policies are then derived from this deep understanding of the world's dynamics (GE-Act) and validated and refined within a sophisticated simulator (GE-Sim). The emphasis is on understanding and predicting the physical world's evolution, allowing for internal "rehearsal" of actions and a focus on physical consistency.1 This approach could lead to more robust policies in complex or novel physical scenarios, excelling in tasks requiring precise physical interaction, understanding of deformable objects, or complex multi-step plans where accurate future state prediction is critical.
Conversely, Helix employs a Vision-Language-Action (VLA) model.5 Its strength lies in directly mapping perception (visual input) and natural language instructions to robot actions. Helix leverages large pre-trained language/vision models for common-sense reasoning and immediate, direct control. Its "world understanding" is implicitly embedded in the vast knowledge base of its VLM component. The emphasis is on interpreting complex human intent and translating it into precise physical actions.5 This VLA approach may be superior in tasks requiring broad semantic understanding, common-sense reasoning, and adaptability to a wide variety of visually distinct but functionally similar objects, especially in unstructured human environments.
These two approaches, while distinct, are not necessarily competing but rather represent complementary pathways towards achieving advanced generalist AI in physical embodiments. A strong world model, like GE's, can provide rich internal representations of physics, causality, and dynamic object properties, which could significantly enhance planning capabilities, enable more sophisticated long-horizon tasks, and improve error recovery mechanisms. Conversely, a direct VLA approach, like Helix's, excels at rapid, intuitive response to natural language commands and demonstrates broad generalization across a vast array of novel objects and tasks. The ultimate generalist AI system might integrate the strengths of both paradigms. One could envision a VLA model that leverages an internal, generative world model for more sophisticated foresight, counterfactual reasoning, and complex multi-step planning. Alternatively, a powerful world model could be made more directly and intuitively controllable by integrating high-level language understanding for task specification and goal setting. This suggests a future trajectory of convergence or hybridization, where the predictive power of world models synergizes with the intuitive command and broad generalization of VLA systems.
5.2. Architectural Design and Modularity
Genie Envisioner features a clearly modular architecture with distinct, specialized components: GE-Base, GE-Act, and GE-Sim.2 This modularity offers potential advantages in terms of interpretability, allowing researchers and engineers to understand and debug specific functionalities. It also provides flexibility for targeted upgrades or replacements of individual components, for instance, improving only the simulator's fidelity or the action decoder's precision.
Helix, while also having a dual-system architecture (System 1 & System 2), functions within a single neural network.6 This design suggests a more tightly integrated, end-to-end learning approach, spanning from high-level reasoning to low-level physical control. While potentially less transparent for component-wise analysis, this integration might optimize for seamless coordination and emergent behaviors across diverse tasks, potentially leading to more fluid and human-like movements. This architectural difference highlights a fundamental trade-off in designing complex AI systems: modularity (as seen in GE) offers flexibility, maintainability, and targeted improvements, which can be beneficial for research and development; end-to-end integration (as seen in Helix) offers potentially higher performance, efficiency, and emergent capabilities through joint optimization, but can be more challenging to analyze, debug, and modify specific behaviors. The choice reflects different engineering philosophies and strategic priorities for developing advanced robotic intelligence.
5.3. Generalization and Adaptation Strategies
Both models demonstrate impressive generalization capabilities, but across different dimensions. Genie Envisioner excels at cross-embodiment generalization.1 It is capable of adapting its learned policies to entirely new robot platforms, such as Dual Franka and Agilex Cobot Magic, with remarkably minimal additional data—requiring "only 1 hour of embodiment- and task-specific teleoperation data for post-training".1 This is achieved by learning a universal "embodied visual space" that captures the essence of manipulation across different physical forms.1 This strength is highly valuable for robot manufacturers and researchers aiming to deploy the same core AI intelligence across a diverse fleet of robots with varying physical configurations.
Helix, on the other hand, exhibits robust generalization across a vast range of tasks and novel objects within a humanoid embodiment.5 Its "pick up anything" capability and the use of "one neural network" for all behaviors underscore its ability to generate on-the-fly behaviors driven by natural language, without requiring task-specific fine-tuning for each new scenario.5 This strength is crucial for deploying a single robot type (humanoid) into highly varied, unpredictable, and dynamic environments, such as a home, where the specific tasks and objects encountered are constantly changing and often unforeseen.
This distinction highlights two equally critical, yet orthogonal, dimensions of generalization in robotics. The pursuit of truly generalist robots suggests that the ideal system might ultimately need to master both forms of generalization. A future system that can quickly adapt its intelligence to novel robot hardware and simultaneously handle an expansive range of novel tasks and objects within that hardware would represent the pinnacle of embodied AI. This suggests that future research and development efforts might increasingly explore how to combine and integrate these two powerful forms of generalization to create truly universal robotic intelligence.
5.4. Control Granularity and Embodiment Focus
Genie Envisioner's control capabilities are described with an emphasis on enabling "fine-grained control of deformable objects" and generating "low-latency motor commands".1 Its performance is detailed by its ability to generate "54-step torque trajectories" within 200 ms.3 While applicable to various robotic platforms, its demonstrations and descriptions primarily emphasize general robotic manipulation arms. The focus on torque trajectories and deformable object manipulation suggests a deep understanding of underlying physical dynamics, which is highly valuable for a wide range of industrial, logistical, or research manipulation tasks.
Helix is specifically designed for "generalist humanoid control".5 It offers "full-upper-body control" with 35 DoF, including precise control over individual fingers, wrists, torso, and head.5 This extensive level of control is crucial for achieving human-like dexterity and seamless interaction in human-centric environments. While both models aim for high-precision control, their specific focus and granularity are tailored to their target embodiments and application domains. The fundamental choice of target embodiment (e.g., a general robotic arm vs. a humanoid robot) directly influences the required control granularity, the specific motor skills that need to be mastered, and consequently, the unique challenges that each model addresses.
5.5. Deployment Considerations and Commercial Readiness
Both Genie Envisioner and Helix are designed with practical deployment in mind, but their strategic approaches differ. Genie Envisioner's paper mentions its capability for "real-time generation... on commodity hardware" 3, indicating its practical deployability. Crucially, AgiBot has stated its intention to make all code, models, and benchmarks related to the platform open source.4 AgiBot's decision to open-source GE could significantly accelerate research and development across the entire robotics community, fostering rapid iteration, broader adoption, and potentially establishing GE's framework as an industry standard for world modeling. This strategy prioritizes widespread scientific and engineering impact.
Helix is explicitly designed for immediate commercial deployment, running "entirely onboard embedded low-power-consumption GPUs".5 This eliminates the need for bulky external servers or cloud dependency, making it highly self-sufficient and practical for real-world applications.7 Figure AI's business model is centered on deploying humanoid robots to address labor shortages across various industries and eventually in homes.8 In contrast to AgiBot's open-source approach, Figure AI's focus on a commercially ready, self-contained system allows for immediate market entry, addressing specific labor market needs and generating revenue. This strategy prioritizes direct commercial application and proving real-world utility. These represent two distinct, yet equally valid, strategies for driving progress in robotics. Open-sourcing aims to democratize access and accelerate the collective advancement of the field, potentially leading to unforeseen innovations built upon the foundation, while commercialization aims to capture market share, demonstrate practical value, and solve real-world problems at scale. Both paths are critical for the advancement of embodied AI, but they operate on different timelines and through different mechanisms of influence.
5.6. Strengths, Limitations, and Unique Contributions of Each Model
Genie Envisioner Strengths:
Unified Framework: Integrates policy learning, evaluation, and simulation into a single, closed-loop system, enhancing efficiency and scalability.1
Strong World Modeling: Provides a robust, vision-centric understanding of physical dynamics, crucial for complex manipulation.1
Cross-Embodiment Generalization: Demonstrates exceptional ability to adapt to new robot hardware with minimal additional data.1
Robust Simulation: GE-Sim is trained on failure-augmented data, leading to more resilient policies.3
Low-Latency Control: Asynchronous inference enables real-time, fine-grained motor commands.1
Open-Source Potential: Planned open-source release could foster significant community impact and adoption.4
Genie Envisioner Potential Limitations:
While powerful for general manipulation, its direct applicability to complex, full-body humanoid control or highly diverse, unstructured human environments (like a home) might require further architectural adaptations beyond its current stated scope, as its demonstrations primarily focus on robotic arms.
Helix Strengths:
Unprecedented Humanoid Dexterity: Achieves full-upper-body control with 35 DoF, including individual fingers, enabling human-like manipulation.5
Multi-Robot Collaboration: Pioneering capability to control multiple robots simultaneously from a single AI instance for shared tasks.5
Exceptional Task and Novel Object Generalization: Driven by natural language, it can generate on-the-fly behaviors for unseen items, significantly reducing training effort.5
Commercial Readiness: Designed for immediate deployment, running efficiently on onboard embedded GPUs without cloud dependency.5
Single Neural Network: A unified architecture for all behaviors, promoting broad transfer learning.5
Helix Potential Limitations:
Its strong focus on humanoid form factors might limit its direct transferability or efficiency for other robotic embodiments without significant re-architecture.
While leveraging vast VLM knowledge, the underlying model might implicitly derive physical understanding, potentially lacking the explicit, fine-grained predictive capabilities that a dedicated generative world model (like GE-Base) provides for truly novel or complex physical interactions.
Unique Contributions:
Genie Envisioner: The introduction of a unified, closed-loop, video-generative world foundation platform that intrinsically integrates learning, simulation, and evaluation.1
Helix: The development of the first generalist VLA model to achieve full-upper-body humanoid control, multi-robot collaboration, and on-the-fly behavior generation for novel items, all within a single neural network architecture.5
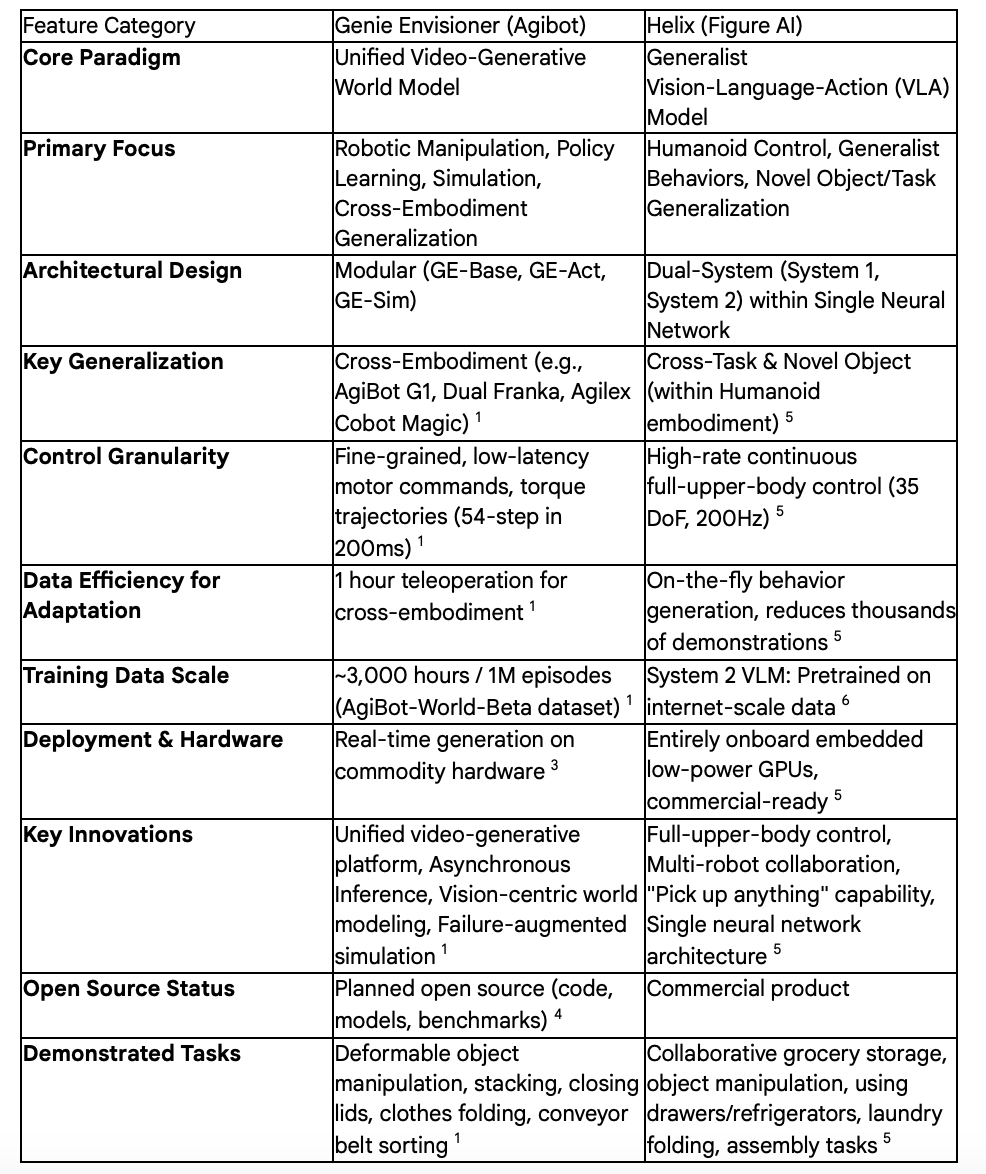
Table: Feature Comparison Matrix
6. Implications for the Future of Robotics and AI
The advancements embodied by Agibot's Genie Envisioner and Figure AI's Helix signify a pivotal moment in the trajectory of robotics and artificial intelligence. These models are not merely incremental improvements but represent foundational shifts that will profoundly impact robot development, deployment, and human-robot interaction.
Impact on Robot Development and Deployment
The emergence of models like GE and Helix underscores a critical trend: the shift towards foundation models as the core building blocks for robotics. Both are described as "foundation" models, with GE as a "unified world foundation platform" 1 and Helix as a "generalist VLA model" 5 leveraging a 7-billion-parameter VLM. This indicates a move away from building task-specific robots from scratch towards developing large, pre-trained, general-purpose models that can be adapted or fine-tuned for a wide array of tasks and environments. This mirrors the successful paradigm seen in natural language processing with large language models (LLMs) and in computer vision. The success of these foundation models implies a future where robotic capabilities will scale rapidly, democratizing robotics development by allowing more researchers and companies to build on powerful, pre-existing foundations rather than reinventing the wheel.
This new paradigm directly accelerates development cycles. GE's unified platform, which integrates learning, simulation, and evaluation in a closed loop, inherently streamlines the process of policy refinement and validation.1 Similarly, Helix's ability to generate "on-the-fly behaviors" and its "single neural network" approach significantly reduce the need for extensive human programming or thousands of demonstrations for new tasks.5 This drastically cuts down the cost and time historically associated with scaling robot capabilities.
Furthermore, these models enable the expansion of deployable environments. Traditional robotics has been largely confined to controlled industrial settings. Helix, with its explicit focus on the "home" environment, demonstrates the capability to handle the immense variability and unpredictability of human-centric spaces.5 GE's robust world modeling and cross-embodiment generalization allow its intelligence to be rapidly adapted to diverse robotic hardware, facilitating broader deployment across various industrial and logistical applications.1 This collective progress signifies a fundamental shift from specialized robots to truly generalist, adaptable systems.
Impact on Human-Robot Interaction
The advancements in both models promise more intuitive and seamless human-robot interaction. Helix's strong natural language understanding capabilities allow users to command robots using everyday speech, enabling more natural and accessible control.5 This moves beyond rigid programming interfaces towards a more human-like communication paradigm.
GE's sophisticated world modeling and simulation capabilities contribute to improved safety and reliability. By accurately predicting the consequences of actions and learning from "failure-augmented data" in simulation, GE can develop more robust and resilient policies, reducing unexpected behaviors in real-world scenarios.3 This enhanced understanding of physical dynamics is crucial for safe interaction in shared human-robot workspaces. Moreover, Helix's pioneering multi-robot collaboration from a single AI instance demonstrates the potential for more complex and efficient human-robot teams, where robots can work together and with humans on shared, long-horizon tasks.5
Potential Areas of Synergy or Competition
While distinct, GE and Helix represent approaches that could either compete or synergize. In certain application domains, a general manipulation platform (like those powered by GE) might compete directly with humanoid robots (like those powered by Helix) if the task can be performed by either. However, the more compelling future likely involves synergy. One could envision a powerful VLA model like Helix leveraging an internal, generative world model akin to GE-Base for more sophisticated foresight, counterfactual reasoning, and complex multi-step planning. This would provide Helix with a deeper, physically grounded understanding of its environment. Conversely, GE's robust world model could be made more directly and intuitively controllable by integrating high-level language understanding and common-sense reasoning derived from VLA architectures, enhancing its ability to interpret abstract human commands for task specification and goal setting. This suggests a future trajectory of convergence or hybridization, where the predictive power of world models synergizes with the intuitive command and broad generalization of VLA systems.
Future Research Directions and Challenges
The path forward for generalist embodied AI involves several critical research directions and challenges:
Scaling Foundation Models: Further scaling of foundation models for even broader generalization across tasks, objects, and environments remains a key challenge. This is directly tied to the increasing importance of data scale and diversity in embodied AI. GE-Base's training on "approximately 3,000 hours of video-language paired data spanning over one million real-world robotic manipulation episodes" 1 and Helix's System 2 VLM being "pretrained on internet-scale data" 6 highlight that the ability of these models to generalize is directly enabled by the vast and diverse datasets they are trained on. This trend indicates that data collection, curation, and annotation for embodied AI will become an increasingly critical and resource-intensive aspect of development. The future success of generalist robotics will heavily depend on the availability and quality of massive, diverse, and multimodal datasets that capture the complexity of real-world interactions. This will likely drive collaborations for data sharing and the development of more efficient data synthesis techniques, such as through advanced simulators like GE-Sim.
Bridging High-Level Reasoning and Low-Level Control: While Helix's dual-system architecture is a significant step, seamlessly integrating abstract reasoning with precise, real-time physical control remains an ongoing challenge.
Robust Evaluation Benchmarks: Developing comprehensive and standardized evaluation benchmarks for generalist embodied AI is crucial to objectively measure progress and compare different approaches.
Safety, Ethics, and Societal Implications: As robots become more autonomous and general-purpose, addressing safety, ethical considerations, and broader societal implications becomes paramount.
The Role of Synthetic Data: The capabilities of simulators like GE-Sim, particularly their training on failure-augmented data, will become increasingly vital for generating high-quality synthetic data to train and validate increasingly capable models, reducing reliance on costly and time-consuming real-world data collection.
7. Conclusion
Agibot's Genie Envisioner and Figure AI's Helix represent distinct yet equally significant leaps forward in the pursuit of general-purpose embodied intelligence. Genie Envisioner advances robotics through its pioneering unified world-modeling and simulation capabilities, enabling efficient policy learning and robust cross-embodiment generalization. Its vision-centric approach provides a deep, predictive understanding of physical dynamics, crucial for complex manipulation tasks. Helix, conversely, pushes the boundaries of humanoid control with its generalist Vision-Language-Action approach, enabling unprecedented full-upper-body dexterity, multi-robot collaboration, and remarkable on-the-fly task adaptation driven by natural language. Its innovative dual-system architecture and "one neural network" philosophy address the scalability challenges of deploying versatile humanoids in unstructured human environments.
Collectively, these models demonstrate the viability of moving beyond task-specific automation to intelligent, versatile systems capable of operating in complex, unpredictable environments. They highlight the emerging importance of foundation models in robotics, the critical role of large-scale and diverse data, and the potential for both specialized and integrated architectures to drive progress. While their core paradigms and generalization strategies differ, the long-term trajectory of embodied AI may see a convergence or hybridization of these powerful approaches, combining the predictive power of world models with the intuitive control and broad semantic understanding of VLA systems. These innovations lay critical groundwork for a future where robots can seamlessly integrate into diverse aspects of human life, from industrial tasks to in-home assistance, fundamentally redefining the capabilities of autonomous systems.
Reference:
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation - arXiv, accessed August 14, 2025, https://arxiv.org/html/2508.05635v1
Genie Envisioner: Unified Robotic Platform, accessed August 14, 2025, https://www.emergentmind.com/topics/genie-envisioner-ge
Genie Envisioner: Unified Robotic Manipulation - Emergent Mind, accessed August 14, 2025, https://www.emergentmind.com/papers/2508.05635
AgiBot debuts world's first unified open-source video-generating platform for robot control, accessed August 14, 2025, https://www.globaltimes.cn/page/202508/1340873.shtml
Helix: A Vision-Language-Action Model for Generalist Humanoid Control - Figure AI, accessed August 14, 2025, https://www.figure.ai/news/helix
Figure's Helix: AI that Brings Human-Like Robots to your Home - Analytics Vidhya, accessed August 14, 2025, https://www.analyticsvidhya.com/blog/2025/02/figures-helix/
From Sci-Fi to Reality: Helix Redefines Home Robotics - Resident Magazine, accessed August 14, 2025, https://resident.com/tech-and-gear/2025/04/14/from-sci-fi-to-reality-helix-redefines-home-robotics
Figure AI: What We Know About the Humanoid Robotics Company - Built In, accessed August 14, 2025, https://builtin.com/articles/figure-ai
Figure 02- Today we unveiled the first humanoid robot that can fold laundry autonomously : r/singularity - Reddit, accessed August 14, 2025, https://www.reddit.com/r/singularity/comments/1moc543/figure_02_today_we_unveiled_the_first_humanoid/