
I Built a 20MB Binary That Thinks Before It Codes — Here’s Why $100M+ AI Tools Still Can’t Do This
Published:
Originally published on Substack.
I spent 20 years programming robots. Staubli, ABB, Fanuc — deploying automation systems for BMW, Tesla, Mercedes, Audi. I built IIoT platforms from scratch. Founded three startups, exited three. Led product for humanoid robotics at a Series A company.
Then I started using AI coding tools, and something felt deeply wrong.
Not wrong in the way most people complain about — hallucinations, wrong syntax, missing context. Those are surface problems. The deeper problem is structural.
Every AI coding tool I tried — Cursor, Aider, Claude Code, Codex CLI — does exactly the same thing: you describe a task, it generates output, and then you become the reviewer. You check the code. You find the gaps. You re-prompt with corrections. You iterate 3, 4, 5 times until the output is shippable.
The AI generates. You iterate.
After two decades of building automation systems that actually close the loop — robots that sense, act, evaluate, and adjust in real time — watching AI coding tools operate as open-loop systems felt like going backwards 30 years. A robot arm that welded a seam and didn’t check its own work would be pulled off the factory floor in a day.
So I asked a question that nobody in the AI coding tools space seemed to be asking:
Why doesn’t the AI review its own work before showing it to me?
That question became OpenKoi.
The Draft Generator Problem
Here’s the state of AI coding tools in 2026. The market is exploding — Cursor raised at a $10B valuation, Devin raised $175M, Aider has 41K GitHub stars. Hundreds of millions of dollars are pouring into this category.
And every single one of these tools has the same fundamental architecture: one-shot generation.
You prompt. The AI generates. Done.
Some have added surface-level improvements. Devin now “autofixes review comments.” Cursor added BugBot for code review. These are band-aids on a structural problem. None of them have built a systematic evaluation loop — a system where the AI scores its own output against quality rubrics, identifies deficiencies, and iterates until a threshold is met.
Think about what this means for your daily workflow. Research suggests developers using AI coding tools spend 30-60 minutes per day re-prompting, reviewing, and manually fixing AI-generated output. That’s not an assistant. That’s a draft generator with a chat interface.
The economic waste is staggering. At senior engineer compensation rates, that’s $15K-$30K per developer per year spent being the AI’s QA department.
But the cost in frustration is worse than the cost in dollars. Every developer I talk to has the same experience: they adopted an AI coding tool expecting to ship faster, and instead they gained a new job — reviewing mediocre first drafts and coaching a system that forgets everything by the next session.
The philosophical problem is clear: an AI agent that calls itself intelligent should review its own work before handing it to you. You shouldn’t have to be the quality gate for a tool that has access to the same tests, linters, and type checkers you do.
If you map the competitive landscape on two axes — self-iterating vs. one-shot, and local/open vs. cloud/closed — something interesting emerges:
Self-Iterating
^
|
OpenKoi *
|
---------------+---------------> Local/Open
Cloud/Closed |
|
Devin * | * Aider
| * Claude Code
Cursor * | * Amp
| * Codex CLI
|
v
One-Shot
Every major AI coding tool clusters in the bottom half. OpenKoi sits alone in the top-right quadrant: self-iterating AND local/open. That’s not an incremental improvement. It’s a different category.
Executive Function as a Service
When I started designing OpenKoi, I didn’t start with features. I started with a question from my robotics background: what kind of mind does a reliable agent need?
In robotics, we learned decades ago that reliable systems need a control hierarchy. You don’t give the end effector direct access to high-level goals. You have a planner, a controller, and an actuator — each with different authority levels and different failure modes.
The same principle applies to AI agents, but nobody has implemented it. Most AI coding tools are workers all the way up. They optimize for task completion without ever asking whether the task should be completed that way, whether the approach is safe, or whether the output is actually correct.
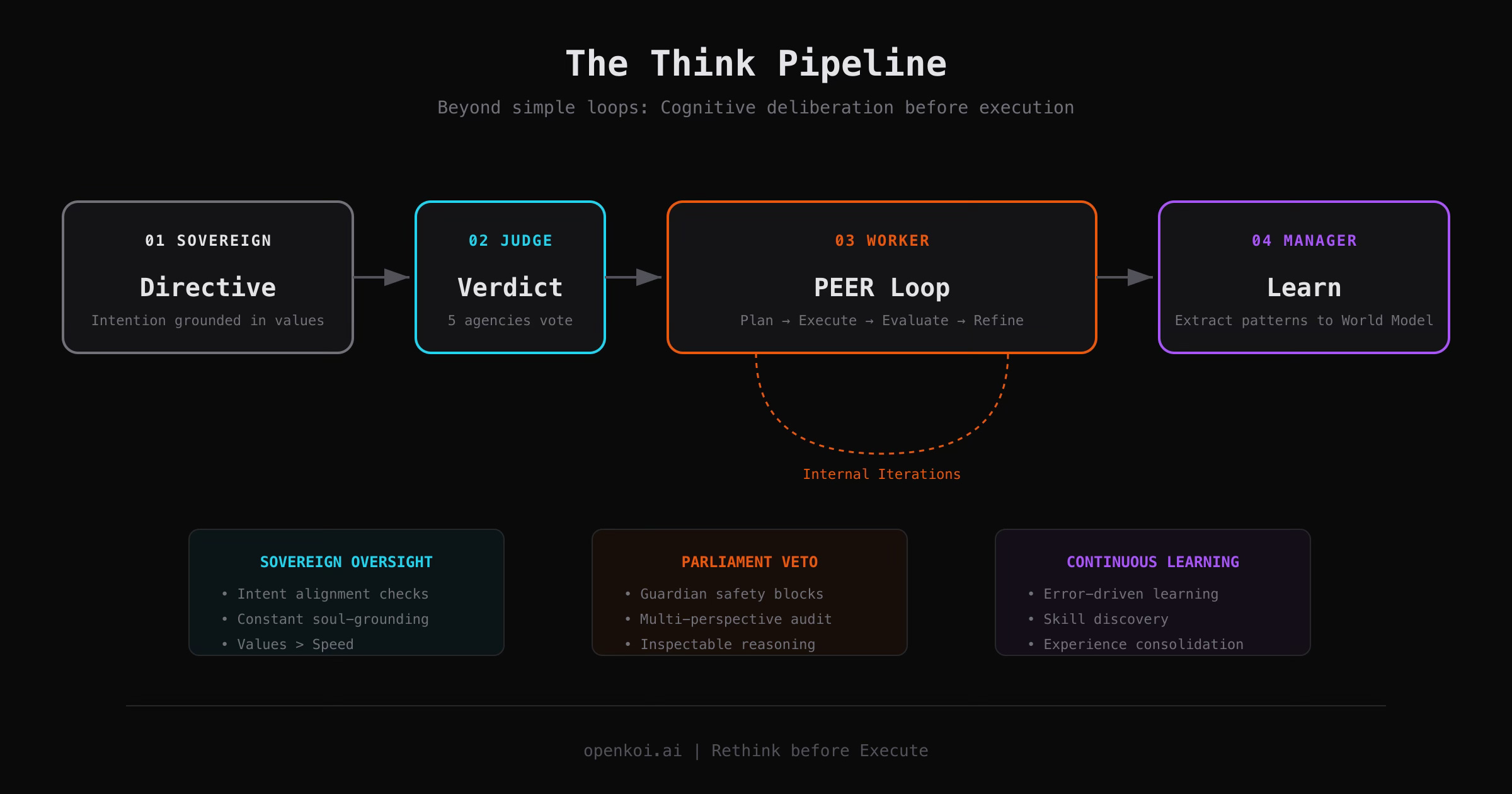
OpenKoi implements what I call Executive Function as a Service (EFaaS) — a three-layer cognitive hierarchy inspired by Minsky’s Society of Mind:
The Sovereign is the identity layer. It’s not a planner — it’s a value system. It holds your preferences, your standards, your constraints. When you run openkoi think "refactor auth to use JWT", the Sovereign frames that task with context: “This developer values security-first code, wants full test coverage, prefers concise implementations.” The Sovereign defines “The Good” — what a successful outcome looks like for you specifically.
The Parliament is where it gets interesting. Five specialized agencies deliberate on every task before a single line of code is written:
AgencyIts JobWhat It ChecksGuardianSafety & reversibilityCan this be undone? What’s the blast radius?EconomistCost & efficiencyHow many tokens will this cost? Is it worth it?EmpathHuman contextWhat does the user actually need? What’s the tone?ScholarFactual accuracyAre the facts correct? Is there enough evidence?StrategistLong-term impactDoes this solve today’s problem but create tomorrow’s?
Each agency votes independently — APPROVE, APPROVE with caveats, ABSTAIN, or BLOCK. The Guardian can unilaterally block any action it deems irreversible or high-risk. The Sovereign Directive can never override a Guardian block. Safety trumps everything.
This is not multi-agent swarm overhead. It’s a single structured prompt that forces deliberation. The cost is negligible. The value is that the agent hesitates before acting — not from indecision, but from genuine consideration of risk, cost, accuracy, and impact.
The Worker is the most constrained layer. It executes only what the Parliament approves, within the boundaries the Sovereign defines. The paradox of agency: the part that actually does things must be the part with the least freedom.
Here’s what a Parliament deliberation looks like in your terminal:
$ openkoi think "delete the staging database" --verbose
GUARDIAN -- BLOCK
Reversibility: NONE -- database deletion is permanent
Blast radius: HIGH -- all staging data lost
Permission level required: ELEVATED
"I cannot approve this without explicit human confirmation.
History shows this database was last referenced 2 hours
ago by the test suite."
ESCALATION
The Guardian has blocked this action.
To proceed, confirm with:
openkoi think "delete the staging database" --override
No other AI coding tool in existence does this. They would just delete the database.
The Engine: Plan-Execute-Evaluate-Refine
The Sovereign-Parliament stack makes the decisions. The PEER loop does the work.
Here’s what happens when you run openkoi think "refactor auth module to use JWT":
$ openkoi think "refactor auth module to use JWT"
[SOVEREIGN] "Direct, test-driven, security-conscious"
[PARLIAMENT] Guardian=APPROVE Economist=APPROVE Scholar=APPROVE+
[EXEC] Rewriting token.rs, middleware.rs, handlers.rs
[EVAL] correctness=9.2 safety=9.5 style=8.8
[REFN] Style below 9.0 -- tightening error types
[EVAL] correctness=9.4 safety=9.5 style=9.3
[LEARNED] "JWT refresh tokens need constant-time comparison"
Done. 3 iterations. 4 files changed.
Four stages, running in a loop:
Plan. Analyze the task. Select relevant skills from the skill registry. Estimate how many iterations this will take. Build a strategy.
Execute. Write the code using the assigned model and available tools — MCP servers, WASM plugins, Rhai scripts. Full tool access, tightly sandboxed.
Evaluate. This is where OpenKoi diverges from every other tool. The output is scored against real evaluators — not a vibes check, but structured rubrics with weighted dimensions:
Test runner — does the code pass existing tests?
Static analysis — does it pass linting and type checking?
LLM judge — domain-specific evaluator skills (code-review, SQL safety, API design, test quality) score the output across multiple dimensions
If the evaluator scores are below threshold (default 0.8, configurable), the agent doesn’t hand you mediocre output and say “here, fix this.” It identifies the specific deficiencies and feeds them back into the next iteration.
Refine. The agent takes the evaluation feedback, compresses the context (to save tokens), and iterates. Not blindly — with targeted feedback about what specifically needs improvement.
The engine has circuit breakers everywhere. Token budget limits. Time budget limits. Max iteration caps. Regression detection — if the score gets worse between iterations, the agent stops and returns the best previous result. It knows when to stop, and it knows when to stop early if the output is already good enough.
Between iterations, the engine is token-frugal: context compression, evaluation caching, diff-patch logic instead of full regeneration. You’re not paying for redundant token burn. You’re paying for targeted refinement.
The default iteration limit is 3. For most tasks, that’s enough. For complex multi-file refactors, you can push it to 5 or higher. The agent will use as many iterations as it needs and no more.
A 20MB Binary in a World of Bloatware
OpenKoi ships as a single static Rust binary. Here are the numbers:
MetricOpenKoi (Rust)Typical Python/Node CLIStartup time< 10ms200-500msIdle memory~5MB50-100MBBinary size~20MB100MB+ with runtimeDependenciesZero runtime depsvirtualenv / node_modules
I chose Rust not because it’s fashionable (though the r/rust crowd will appreciate this). I chose it because when an AI agent runs as a background daemon processing long-running tasks, or operates on a developer’s laptop alongside 47 Chrome tabs, the difference between 5MB and 100MB of idle memory matters. The difference between 10ms and 500ms startup matters when the agent is invoked hundreds of times a day.
The stack: Tokio for async concurrency, Axum for the HTTP API, Ratatui for the TUI dashboard, rusqlite + sqlite-vec for persistent memory with vector similarity search, Wasmtime for sandboxed WASM plugins. Everything is statically linked. No system OpenSSL. No system SQLite. Download one file. Run it.
Any Model, Any Provider
OpenKoi works with 8+ LLM providers out of the box: Anthropic, OpenAI, Google, AWS Bedrock, Ollama, Groq, DeepSeek, Moonshot/Kimi, xAI, Qwen, Together, OpenRouter — plus any OpenAI-compatible endpoint.
But here’s the part that makes people’s eyes widen: subscription-based access via OAuth. If you have a GitHub Copilot subscription or a ChatGPT Plus/Pro subscription, you can authenticate via device-code flow and use frontier models through OpenKoi at zero additional cost.
openkoi connect copilot # GitHub login, done
openkoi connect chatgpt # OpenAI login, done
You’re already paying for these subscriptions. OpenKoi lets you use them for self-iterating agentic coding. No one else does this.
You can also assign different models to different roles — a fast model for evaluation, a powerful model for execution, a cheap model for planning. The agent auto-resolves the best available model from your configured providers.
Local-First, Always
All data stays on your machine. Session transcripts, learnings, patterns, credentials — everything lives in a local SQLite database. No cloud backend. No telemetry. No account required. The only network calls are to LLM providers for model inference, and you control which providers those are.
Six Commands to Inspect an AI’s Mind
Every other AI coding tool is a black box. You see the output. You don’t see how it decided.
OpenKoi is a glass box. Six cognitive commands expose the full deliberation pipeline:
openkoi think "task" — The full EFaaS pipeline: Sovereign directive, Parliament deliberation, PEER iteration, learning extraction.
openkoi soul show — See the agent’s identity, values, and trajectory. The soul evolves based on your feedback and interaction patterns. It’s entirely optional, but over time it creates a personalized agent that knows your coding style, your preferences, your standards.
openkoi mind parliament — See the last Parliamentary deliberation. Which agencies approved? Which had caveats? Was there dissent? openkoi mind calibrate shows how accurate each agency’s predictions were against actual outcomes.
openkoi world tools — See the Tool Atlas: which tools the agent has used, their reliability scores, known failure modes, and workarounds it has learned. openkoi world human shows what the agent has learned about your preferences.
openkoi reflect today — Today’s decisions, outcomes, and self-assessment. openkoi reflect honest runs an epistemic audit: where was the agent overconfident? Where was it wrong? What did it learn?
openkoi trust show — Delegation levels per domain. You can grant the agent increasing autonomy in domains where it has demonstrated accuracy: openkoi trust grant auth-module act. Revoke anytime. Audit every autonomous action.
The --simulate flag deserves special mention. It runs the full cognitive pipeline without taking any action — “chess mode.” The agent simulates multiple futures and shows you what would happen:
$ openkoi think "send the weekly report email" --simulate
SIMULATION ONLY (no actions will be taken)
Future A: Send now (8:55 AM)
3 recipients in CET will see it at 1:55 AM
Likely response rate: LOW (out of hours)
Future B: Schedule for 9:00 AM CET (3:00 PM your time)
All recipients in business hours
Likely response rate: HIGH
Recommendation: Future B
Champion: Empath ("don't look careless about timezone")
Dissent: Economist ("just send it now, saves time")
This is what it means for an AI to think before it acts. Not just “generate faster.” Think.
The Agent That Gets Smarter Because It Failed
Most AI coding tools forget everything between sessions. Every interaction starts from zero. You re-teach the same corrections, explain the same preferences, work around the same failure modes.
OpenKoi has three feedback timescales:
Tight (seconds): Per-task outcome analysis. After every task, the agent records what worked, what failed, and what it learned. Tool reliability scores update in real time.
Medium (hours/days): Pattern mining. The agent observes your daily usage and detects recurring workflows. When it spots a pattern, it proposes a new skill — a SKILL.md file that codifies the pattern so it can be applied automatically next time. Review proposed skills with openkoi learn.
Deep (weeks): Soul evolution. Over time, the agent’s understanding of your values, preferences, and working style deepens. This isn’t a configuration file — it’s a living model that evolves through interaction.
The maturity model has four stages:
Competent Executor — Completes assigned tasks reliably. Knows the boundaries of its competence.
Proactive Advisor — Anticipates needs. Notices patterns you haven’t articulated. Offers unsolicited but welcome suggestions.
Trusted Delegate — Authorized to act without explicit instruction in defined domains. You trust the agent’s judgment enough to delegate.
Sovereign Partner — Has a coherent model of your values, goals, and trajectory. Makes decisions you would endorse but haven’t explicitly considered.
Stages unlock through accumulated trust, not feature additions. The agent earns delegation through demonstrated accuracy.
As the JARVIS Vision document that guided OpenKoi’s design states: “The strength of an agent is not in its intelligence, but in the tightness of its feedback loops.”
Stop Babysitting Your AI
OpenKoi is MIT-licensed, fully open source, and available now.
Three steps:
# 1. Install
curl -fsSL https://openkoi.ai/install.sh | sh
# or
cargo install openkoi
# 2. Think
openkoi think "refactor the auth module to use JWT tokens"
# 3. Ship — it deliberates, iterates, and learns
No config file needed. OpenKoi auto-discovers your API keys from environment variables, existing CLI tools (Claude CLI, Qwen CLI), macOS Keychain, OAuth tokens, and local Ollama instances. If you have an API key set anywhere on your system, OpenKoi will find it.
The question isn’t whether your AI coding tool should review its own work. The question is why it doesn’t already.
Star the repo: github.com/openkoi-ai/openkoi
Read the docs: openkoi.ai
Follow the journey: @yongqianme on X
OpenKoi is built by Yong Qian — a robotics and AI product leader with 20+ years deploying automation systems for BMW, Tesla, and Mercedes. Three startups founded, three exited. OpenKoi is what happens when someone who spent two decades building closed-loop industrial systems looks at AI coding tools and asks: “Why is this open-loop?”
If this resonated, share it with a developer who’s tired of being their AI’s QA department.